一 需求设计
分布式环境下,保证每个序列号(sequence)是全系统唯一的;
序列号可排序,满足单调递增的规律;
特定场景下,能生成无规则(或者看不出规则)的序列号;
生成的序列号尽量短;
序列号可进行二次混淆,提供可扩展的interface,业务方自定义实现。
二 方案设计
为了满足上述需求,发号器必须能够支持不同的生成策略,最好是还能支持自定义的生成策略,这就对系统本身的可扩展性提出了要求。 目前,发号器设计了两种比较通用的基础策略,各有优缺点,但结合起来,能达到优势互补的目的。
1. segment
第一种策略称之为『分段』(segment),下文将对其进行详细阐述: 整个segment发号器有两个重要的角色:Redis和MongoDB,理论上MongoDB是可以被MySQL或其他DB产品所替代的。 segment发号器所产生的号码满足单调递增的规律,短时间内产生的号码不会有过长的问题(可根据实际需要,设置初始值,比如 100)。
Redis数据结构(Hash类型)
key: <string>,表示业务主键/名称
value: {
cur: <long>,表示当前序列号
max: <long>,表示这个号段最大的可用序列号
}取号的大部分操作都集中在Redis,为了保证序列号递增的原子性,取号的功能可以用Lua脚本实现。
--[[
由于RedisTemplate设置的HashValueSerializer是GenericToStringSerializer,故此处的HASH结构中的
VALUE都是string类型,需要使用tonumber函数转换成数字类型。
]]
local max = redis.pcall("HGET", KEYS[1], "max") --获取一段序列号的max
local cur = redis.pcall("HGET", KEYS[1], "cur") --获取当前发号位置
if tonumber(cur) >= tonumber(max) then --没有超过这段序列号的上限
local step = ARGV[1]
if (step == nil) then --没有传入step参数
step = redis.pcall("HGET", KEYS[1], "step") --获取这段序列号的step配置参数值
end
redis.pcall("HSET", KEYS[1], "max", tonumber(max) + tonumber(step)) --调整max参数值,扩展上限
end
return redis.pcall("HINCRBY", KEYS[1], "cur", 1) --触发HINCRBY操作,对cur自增,并返回自增后的值
注意:在redis执行lua script期间,redis处于BUSY状态,这个时候对redis的任何形式的访问都会抛出JedisBusyException异常,所以lua script中的处理逻辑不得太复杂。
值得一提的是,即使切换到一个新的database,或者开启新线程执行lua script,都将会遇到同样的问题,毕竟redis是单进程单线程的。
如果不幸遇到上述问题,需要使用redis-cli客户端连上redis-server,向其发送SCRIPT KILL命令,即可终止脚本执行。
如果想避免上述问题,也可以直接使用Springboot提供的RedisTemplate,能支持绝大部分redis command。
MongoDB 数据结构
{
bizTag: <string>, 表示业务主键/名称
max: <long>, 表示这个号段最大的可用序列号
step: <int>, 每次分段的步长
timestamp: <long>, 更新数据的时间戳(毫秒)
}MongoDB部分主要是对号段的分配进行管理,一个号段不能多发,也可以根据发号情况,适当放缩号段步长(step)。
到此为止,segment发号器的雏形已经形成了。 一个比较突出的问题是在两个号段衔接的时间点,当一个segment派发完了后,会对MongoDB和Redis中的数据中的max扩容,I/O消耗比正常发号要稍多,会遇到“尖刺”
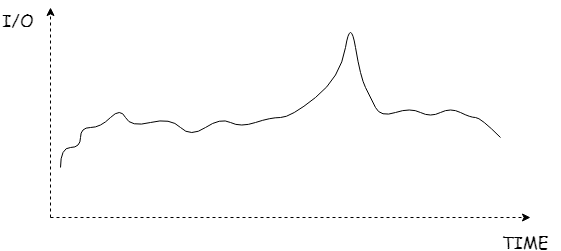
为了消除“尖刺”,可以使用双Buffer模型
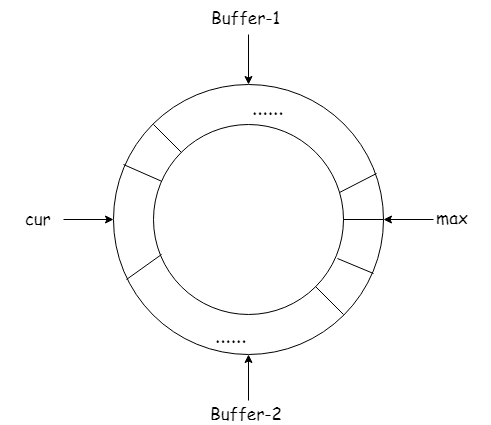
这个模型的核心思想就是“预分配”。可以设置一个阈值(threshold),比如20%,当Buffer-1里面的号段已经消耗了20%,那么立刻根据Buffer-1的max和step,开辟Buffer-2。 当Buffer-1完全消耗了,可以无缝衔接Buffer-2,。
如果Buffer-2的消耗也达到阈值了,又可以开辟Buffer-1,如此往复。
接下来,我们来讨论一下异常/故障情况。
① Redis宕机。因为大部分发号工作都是依靠Redis完成的,所以发生了这种情况是非常糟糕的。如果想有效降低此风险,最行之有效的办法是对Redis进行集群化,通常是1主2从,这样可以挺住非常高的QPS了。 当然也有退而求其次的办法,就是利用上述提到的双Buffer模型。不依赖Redis取号,直接通过程序控制,利用机器内存。所以当需要重启发号服务之前,要确保依赖的组件是运行良好的,不然号段就丢失了。
② 要不要持久化的问题。这个问题主要是针对Redis,如果没有记录下当前的取号进度,那么随着Redis的宕机,取号现场就变得难以恢复了;如果每次都记录取号进度,那么这种I/O高密度型的作业会对服务性能 造成一定影响,并且随着取号的时间延长,恢复取号现场就变得越来越慢了,甚至到最后是无法忍受的。除了对Redis做高可用之外,引入MongoDB也是出于对Redis持久化功能辅助的考虑。 个人建议:如果Redis已经集群化了,而且还开启了双Buffer的策略,以及MongoDB的加持,可以不用再开启Redis的持久化了。 如果考虑到极端情况下,Redis还是宕机了,我们可以使用MongoDB里面存下来的max,就max+1赋值给cur(避免上个号段取完,正好宕机了)。
③ MongoDB宕机。这个问题不是很严重,只要将step适当拉长一些(至少取号能支撑20分钟),利用Redis还在正常取号的时间来抢救MongoDB。不过,考虑到实际可能没这么快恢复mongo服务,可以在程序中采取 一些容错措施,比如号段用完了,mongo服务无法到达,直接关闭取号通道,直到MongoDB能正常使用;或者程序给一个默认的step,让MongoDB中的max延长到max+step*n(可能取了N个号段MongoDB才恢复过来), 这样取号服务也可以继续。依靠程序本身继续服务,那么需要有相关的log,这样才有利于恢复MongoDB中的数据。
④ 取号服务宕机。这个没什么好说的,只能尽快恢复服务运行了。
⑤ Redis,MongoDB都宕机了。这种情况已经很极端了,只能利用双Buffer策略,以及程序默认的设置进行工作了,同样要有相关的log,以便恢复Redis和MongoDB。
⑥ 都宕机了。我有一句mmp不知当讲不当讲……
2、snowflake
第二种策略是Twitter出品,算法思想比较巧妙,实现的难度也不大。
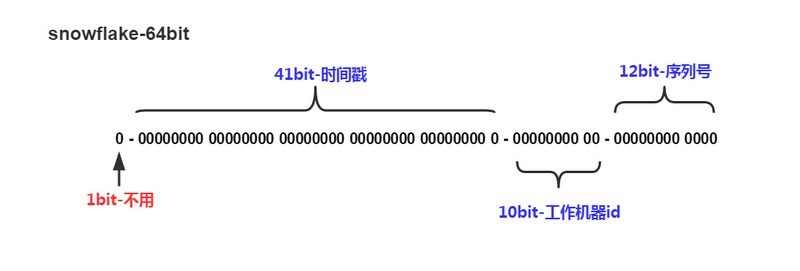
以上示意图描述了一个序列号的二进制组成结构。 第一位不用,恒为0,即表示正整数; 接下来的41位表示时间戳,精确到毫秒。为了节约空间,可以将此时间戳定义为距离某个时间点所经历的毫秒数(Java默认是1970-01-01 00:00:00); 再后来的10位用来标识工作机器,如果出现了跨IDC的情况,可以将这10位一分为二,一部分用于标识IDC,一部分用于标识服务器; 最后12位是序列号,自增长。
snowflake的核心思想是64bit的合理分配,但不必要严格按照上图所示的分法。 如果在机器较少的情况下,可以适当缩短机器id的长度,留出来给序列号。
当然,snowflake的算法将会面临两个挑战:
① 机器id的指定。这个问题在分布式的环境下会比较突出,通常的解决方案是利用Redis或者Zookeeper进行机器注册,确保注册上去的机器id是唯一的。为了解决 强依赖Redis或者Zookeeper的问题,可以将机器id写入本地文件系统。
② 机器id的生成规则。这个问题会有一些纠结,因为机器id的生成大致要满足三个条件:a. int类型(10bit)纯数字,b. 相对稳定,c. 与其他机器要有所区别。至于优雅美观,都是其次了。对于机器id的存储,可以使用HASH结构,KEY的规则是“application-name.port.ip”,其中ip是通过算法转换成了一段长整型的纯数字,VALUE则是机器id, 服务id,机房id,其中,可以通过服务id和机房id反推出机器id。
假设服务id(workerId)占8bit,机房id(rackId)占2bit,从1开始,workerId=00000001,rackId=01,machineId=00000000101 如果用Redis存储,其表现形式如下:
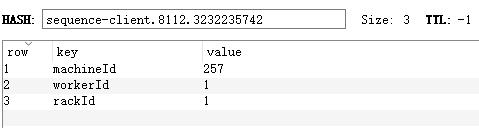
如果存储在文件中(建议properties文件),则文件名是sequence-client:8112:3232235742.properties,文件内容如下:
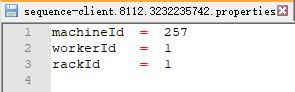
如果发号服务上线,直接按照“application-name.port.ip”的规则取其内容。
③ 时钟回拨。因为snowflake对系统时间是很依赖的,所以对于时钟的波动是很敏感的,尤其是时钟回拨,很有可能就会出现重复发号的情况。时钟回拨问题解决策略通常是直接拒绝发号,直到时钟正常,必要时进行告警。
三 程序设计
整个发号过程可以分成三个层次:
1、策略层(strategy layer):这个层面决定的是发号方法/算法,涵盖了上述所讲的segment和snowflake两种方式,当然,用户也可以自己扩展实现其他发号策略。
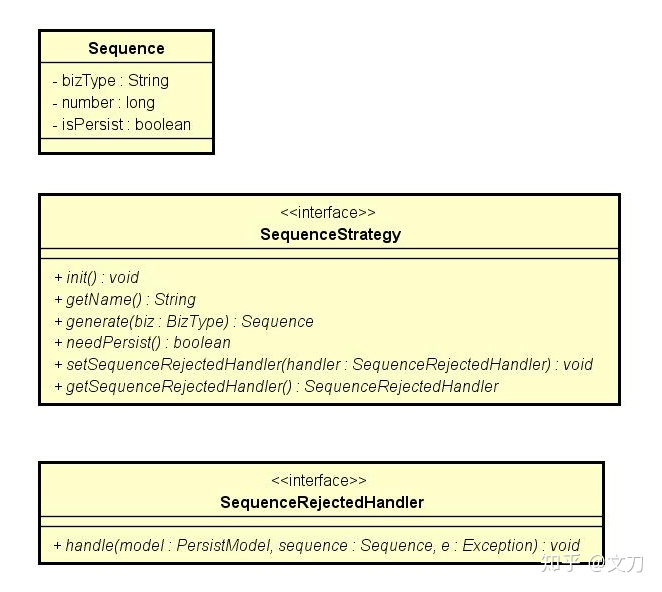
最顶上定义Sequence实际上就是发号的结果。bizType是对发号业务场景的定义,比如订单号,用户ID,邀请好友的分享码。 发号策略的init接口是发号前的初始化工作,而generate接口就是调用发号器的主入口了。 当然,考虑到各种异常情况,加入了拒绝发号的处理器(SequenceRejectedHandler),默认实现只是记录日志,用户可根据需求去实现该处理器,然后用set方法设置发号策略的拒绝处理器。
2、插件层(plugin layer):此处的插件可以理解是一种拦截器,贯穿SequenceStrategy的发号全周期。引入插件后,无疑是丰富了整个发号的操作过程,用户可以从中干预到发号的整个流程,以便达到其他的目的,比如:记录发号历史,统计发号速率,发号二次混淆等。
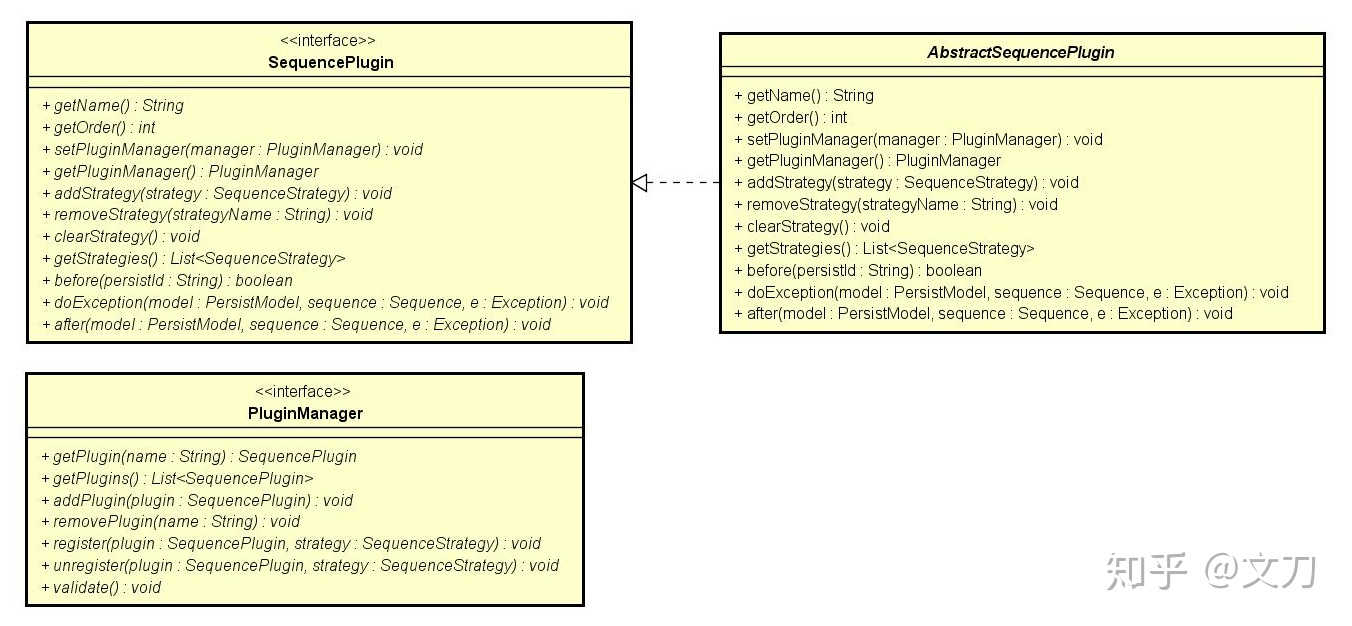
可以看出,插件被设计成『注册式』的,发号策略只有注册了相关插件之后,插件才能生效, 当然,一个插件能被多个发号策略所注册,一个发号策略也能同时注册多个插件,所以两者是多对多的关系,PluginManager的出现就是解决插件的注册管理问题。 从SequencePlugin的定义中可以发现,插件是有优先级(Order)的,通过getOrder()可以获得,在这套发号系统里,Order值越小,表示该插件越优先执行。此外,插件有三个重要的操作: before,表示发号之前的处理。若返回了false,那么该插件后面的操作都失效了,否则继续执行发号流程。 after,表示发号之后的处理。 doException,表示插件发生异常的处理方法。
3、持久层(persistence layer):这个层面指代的是上述所提的MongoDB部分,如果不需要持久化的支持,可以不实现此接口,那么整个发号器就变成纯内存管理的了。
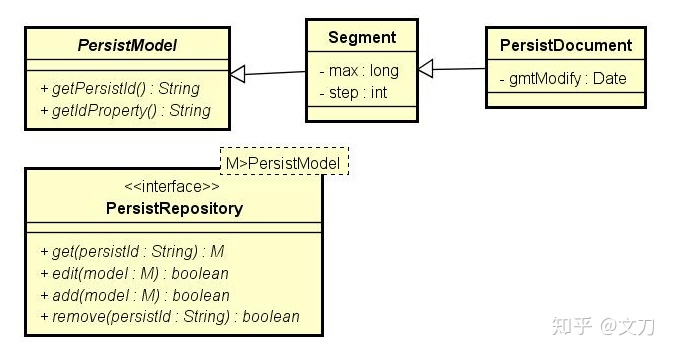
PersistRepository定义了基本的CRUD方法,其中persistId可以理解成上述提到的BizType。 一切的持久化对象都是从PersistModel开始的,上图中的Segment、PersistDocument都是为了实现分段发号器而定义的。
四 总结
这篇文章详细阐述了分布式发号器系统的设计,旨在能做出一个可扩展,易维护的发号系统。业界比较知名的发号算法似乎也不多,整个发号系统不一定就按照笔者所做的设计,还是要立足于具体的业务需求。