1 集群分布式原理
ES集群可以根据节点数, 动态调整主分片与副本数, 做到整个集群有效均衡负载。
单节点状态下:
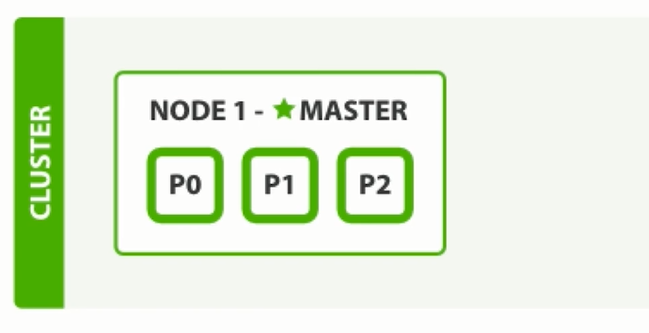
两个节点状态下, 副本数为1:

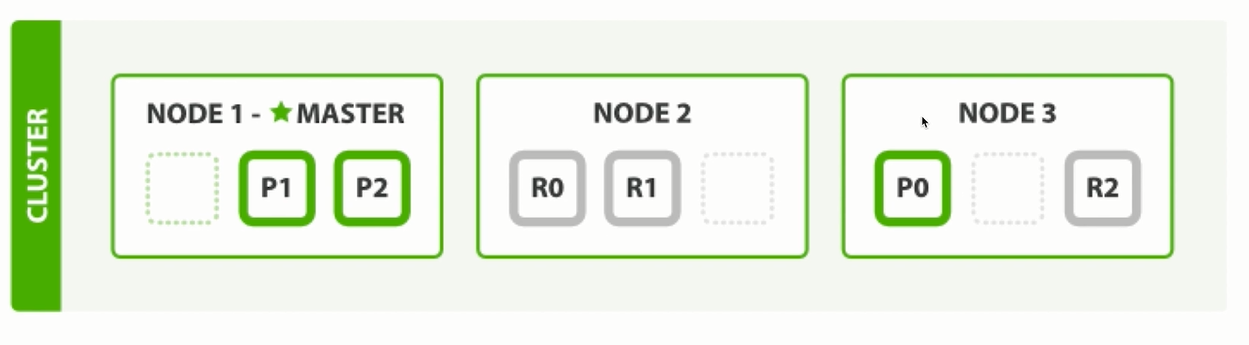
三个节点状态下, 副本数为1:
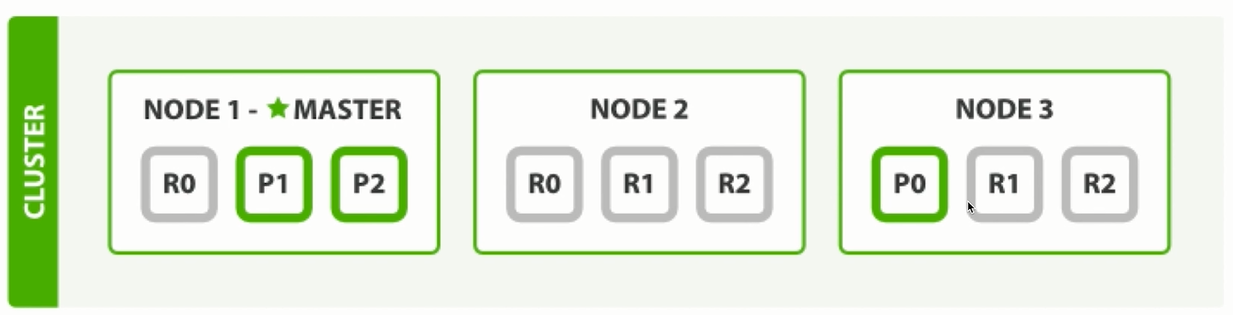
三个节点状态下, 副本数为2:
2 分片处理机制
设置分片大小的时候, 需预先做好容量规划, 如果节点数过多, 分片数过小, 那么新的节点将无法分片, 不能做到水平扩展, 并且单个分片数据量太大, 导致数据重新分配耗时过大。
假设一个集群中有一个主节点、两个数据节点。orders索引的分片分布情况如下所示:
1 | PUT orders |
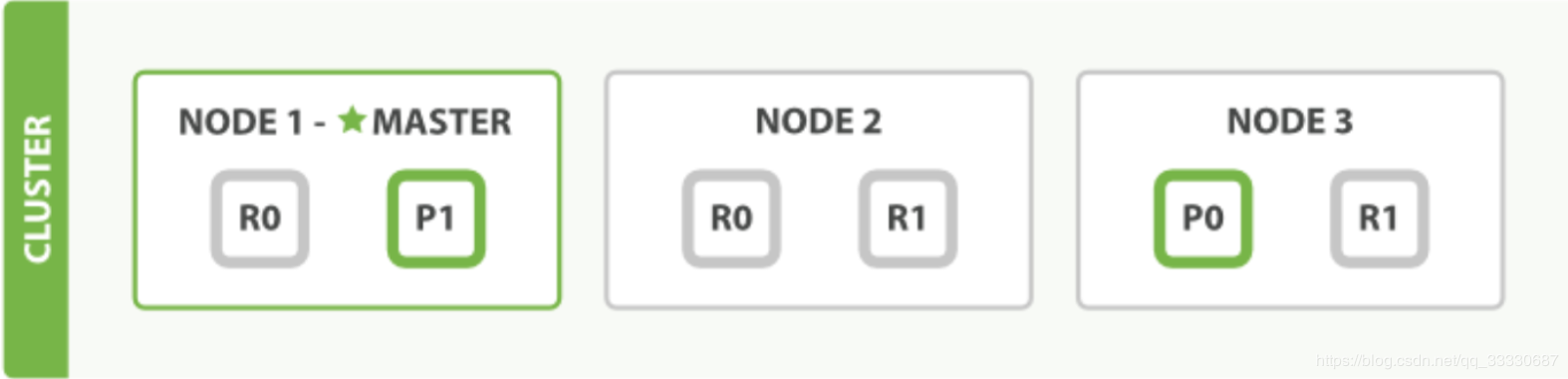
整个集群中存在P0和P1两个主分片, P0对应的两个R0副本分片, P1对应的是两个R1副本分片。
3 新建索引处理流程
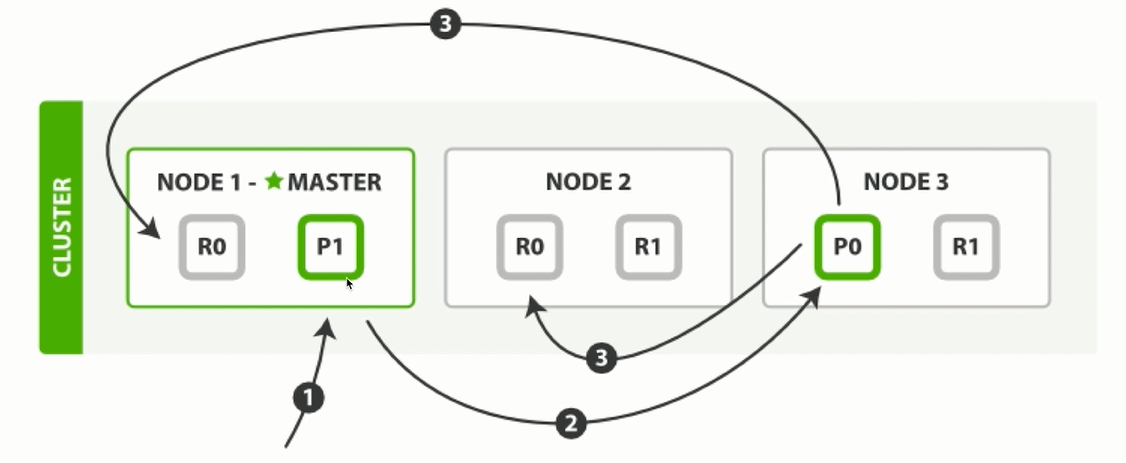
- 写入的请求会进入主节点, 如果是NODE2副本接收到写请求, 会将它转发至主节点。
- 主节点接收到请求后, 根据documentId做取模运算(外部没有传递documentId,则会采用内部自增ID), 如果取模结果为P0,则会将写请求转发至NODE3处理。
- NODE3节点写请求处理完成之后, 采用异步方式, 将数据同步至NODE1和NODE2节点。
4 读取索引处理流程
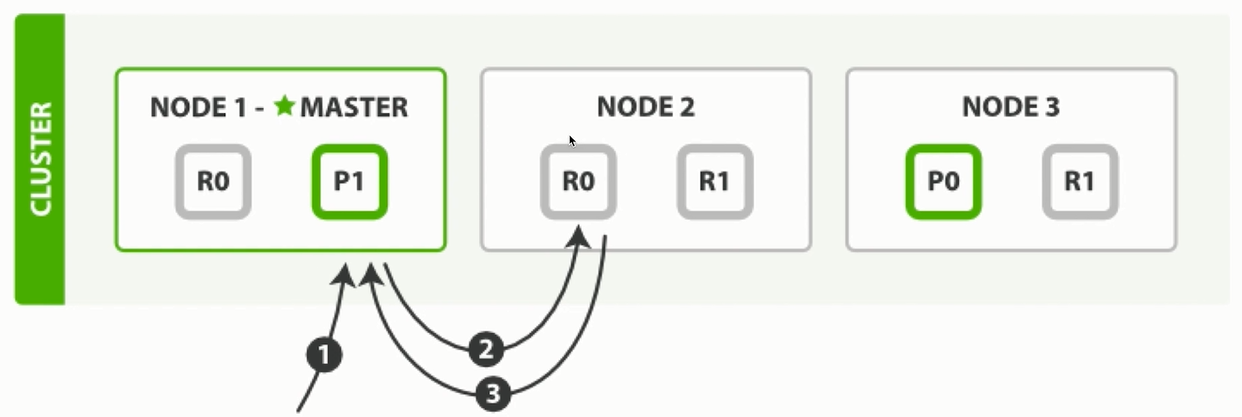
- 读取的请求进入MASTER节点, 会根据取模结果, 将请求转发至不同的节点。
- 如果取模结果为R0,内部还会有负载均衡处理机制,如果上一次的读取请求是在NODE1的R0, 那么当前请求会转发至NODE2的R0, 保障每个节点都能够均衡的处理请求数据。
- 读取的请求如果是直接落至副本节点, 副本节点会做判断, 若有数据则返回,没有的话会转发至其他节点处理。