1. nginx 是怎么找index.php 文件的
当nginx发现需要/web/echo/index.php 文件时, 就会向内核发起 IO 系统调用(因为要跟硬件打交道, 这里的硬件是指硬盘, 通常需要靠内核来操作, 而内核提供的这些功能是通过系统调用来实现的), 告诉内核, 我需要这个文件, 内核从/ 开始找到web 目录, 再在web 目录下找到echo 目录, 最后在echo 目录下找到index.php 文件, 于是把这个index.php 从硬盘上读取到内核自身的内存空间, 然后再把这个文件复制到nginx进程所在的内存空间, 于是 nginx就得到了自己想要的文件了
2. 寻找文件在文件系统层面是怎么操作的
如, nginx 需要得到/web/echo/index.php 这个文件 每个分区(像ext3 等文件系统, block块是文件存储的最小单元, 默认是4096字节) 都是包含元数据区和数据区, 每个文件在元数据区都有元数据条目(一般是128字节大小), 每个条目都有一个编号, 称之为 inode(index node), 这个inode 里包含 文件类型, 权限, 连接次数, 属主和数组的 ID&时间戳, 这个文件占据了哪些磁盘块也就是块的编号(block, 每个文件可以占用多个 block, 且 block 不一定是连续的, 每个 block 都有编号), 如下图:
目录其实也是普通文件, 也需要占用磁盘块, 目录不是一个容器. 默认创建的目录大小为4096字节, 即只需要占用一个磁盘块, 但这是不确定的. 所以要找到目录也是需要到元数据区里找到对应的条目, 只要找到对应的inode就可以找到目录所占用的磁盘块. 目录里存着一张表(映射表), 里面放着 目录或文件的名称和对应的inode号, 如下:
| - | - |
|---|---|
| 文件名称(只是字符串) | inode 号 |
| test.txt | 100 |
假如
1 | / 在数据区占据1, 2号 block, `/` 其实也是一个目录, 里面有两个目录, web 和 111 |
其在文件系统中分布如下图:

那么内核究竟是怎么找到index.php 这个文件的呢? 内核拿到 nginx 的 IO 系统调用要获取/web/echo/index.php 这个文件请求之后,
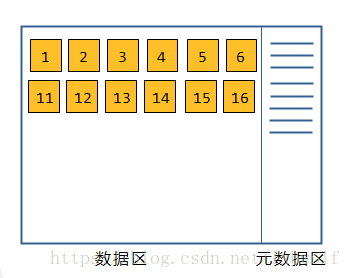
1. 内核读取元数据区 / 的inode, 从 inode 里读取 / 所对应的数据块的编号, 然后在数据区找到其对应的块(1, 2号块), 读取1号块上的映射表找到 web 这个名称在元数据区对应的 inode 号
2. 内核读取 web 对应的 inode(3号), 从中得到 web 在数据区对应的块是5号块, 于是到数据区找到5号块, 从中读取映射表, 知道 echo 对应的 inode 是5号, 于是到元数据区找到5号 inode
3. 内核读取5号 inode, 得到 echo 在数据区对应的事11号块, 于是到数据区读取11号块得到映射表, 得到index.php 对应的 inode 事9号
4. 内核到元数据区读取9号 inode, 得到 index.php 对应的事15号和16号数据块, 于是就到数据区域找到15 16号块, 读取其中的内容, 得到 index.php 的完整内容