快速了解跳表
跳跃表(简称跳表)由美国计算机科学家William Pugh发明于1989年。他在论文《Skip lists: a probabilistic alternative to balanced trees》中详细介绍了跳表的数据结构和插入删除等操作。
跳表(SkipList,全称跳跃表)是用于有序元素序列快速搜索查找的一个数据结构,跳表是一个随机化的数据结构,实质就是一种可以进行二分查找的有序链表。跳表在原有的有序链表上面增加了多级索引,通过索引来实现快速查找。跳表不仅能提高搜索性能,同时也可以提高插入和删除操作的性能。它在性能上和红黑树,AVL树不相上下,但是跳表的原理非常简单,实现也比红黑树简单很多。
链表的优势就是更高效的插入、删除。痛点就是查询很慢很慢!每次查询都是一种O(n)复杂度的操作
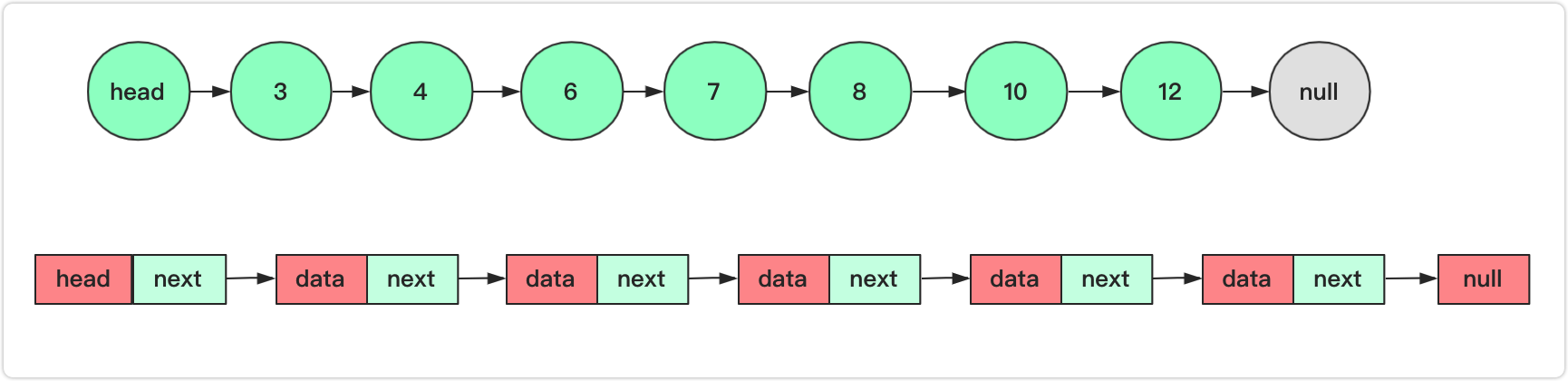
这是一个带头结点的链表(头结点相当于一个固定的入口,不存储有意义的值),每次查找都需要一个个枚举,相当的慢,我们能不能稍微优化一下,让它稍微跳一跳呢?答案是可以的,我们知道很多算法和数据结构以空间换时间,我们在上面加一层索引,让部分节点在上层能够直接定位到,这样链表的查询时间近乎减少一半
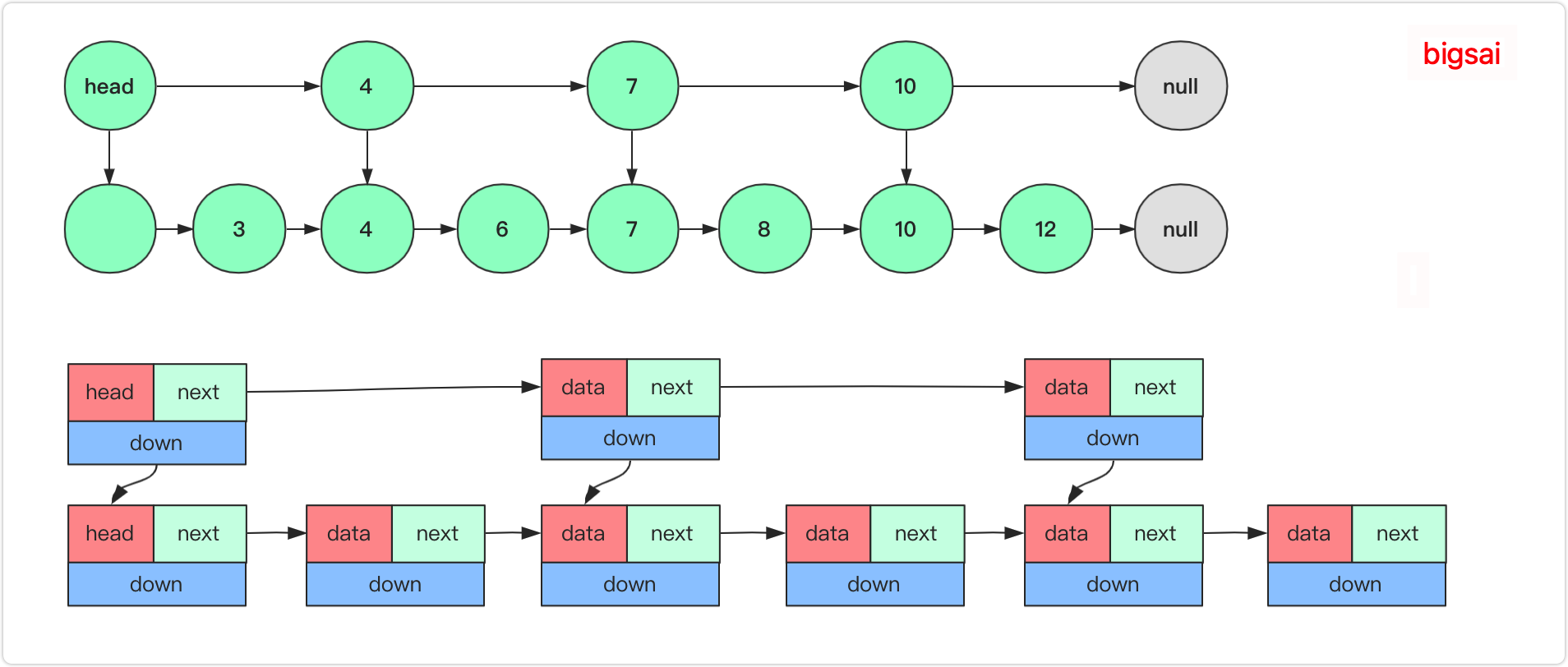
这样,在查询某个节点的时候,首先会从上一层快速定位节点所在的一个范围,如果找到具体范围向下然后查找代价很小,当然在表的结构设计上会增加一个向下的索引(指针)用来查找确定底层节点。平均查找速度平均为O(n/2)。但是当节点数量很大的时候,它依旧很慢很慢。我们都知道二分查找是每次都能折半的去压缩查找范围,要是有序链表也能这么跳起来那就太完美了。没错跳表就能让链表拥有近乎的接近二分查找的效率的一种数据结构,其原理依然是给上面加若干层索引,优化查找速度。

通过上图可以看到,通过这样的一个数据结构对有序链表进行查找都能近乎二分的性能。就是在上面维护那么多层的索引,首先在最高级索引上查找最后一个小于当前查找元素的位置,然后再跳到次高级索引继续查找,直到跳到最底层为止,这时候以及十分接近要查找的元素的位置了(如果查找元素存在的话)。由于根据索引可以一次跳过多个元素,所以跳查找的查找速度也就变快了。
对于理想的跳表,每向上一层索引节点数量都是下一层的1/2.那么如果n个节点增加的节点数量(1/2+1/4+…)<n。并且层数较低,对查找效果影响不大。但是对于这么一个结构,你可能会疑惑,这样完美的结构真的存在吗?大概率不存在的,因为作为一个链表,少不了增删该查的一些操作。而删除和插入可能会改变整个结构,所以上面的这些都是理想的结构,在插入的时候是否添加上层索引是个概率问题(1/2的概率),
跳表的增删改查
在实现本跳表的过程为了便于操作,我们将跳表的头结点(head)的key设为int的最小值(一定满足左小右大方便比较)。
对于每个节点的设置,设置成SkipNode类,为了防止初学者将next向下还是向右搞混,直接设置right,down两个指针。
1
2
3
4
5
6
7
8
9
10
11
| class SkipNode<T>
{
int key;
T value;
SkipNode right,down;
public SkipNode (int key,T value) {
this.key=key;
this.value=value;
}
}
|
跳表的结构和初始化也很重要,其主要参数和初始化方法为:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| public class SkipList <T> {
SkipNode headNode;
int highLevel;
Random random;
final int MAX_LEVEL = 32;
SkipList(){
random=new Random();
headNode=new SkipNode(Integer.MIN_VALUE,null);
highLevel=0;
}
}
|
查询操作
很多时候链表也可能这样相连仅仅是某个元素或者key作为有序的标准。所以有可能链表内部存在一些value。不过修改和查询其实都是一个操作,找到关键数字(key)。并且查找的流程也很简单,设置一个临时节点team=head。当team不为null其流程大致如下:
(1) 从team节点出发,如果当前节点的key与查询的key相等,那么返回当前节点(如果是修改操作那么一直向下进行修改值即可)。
(2) 如果key不相等,且右侧为null,那么证明只能向下(结果可能出现在下右方向),此时team=team.down
(3) 如果key不相等,且右侧不为null,且右侧节点key小于待查询的key。那么说明同级还可向右,此时team=team.right
(4)(否则的情况)如果key不相等,且右侧不为null,且右侧节点key大于待查询的key 。那么说明如果有结果的话就在这个索引和下个索引之间,此时team=team.down。
最终将按照这个步骤返回正确的节点或者null(说明没查到)。
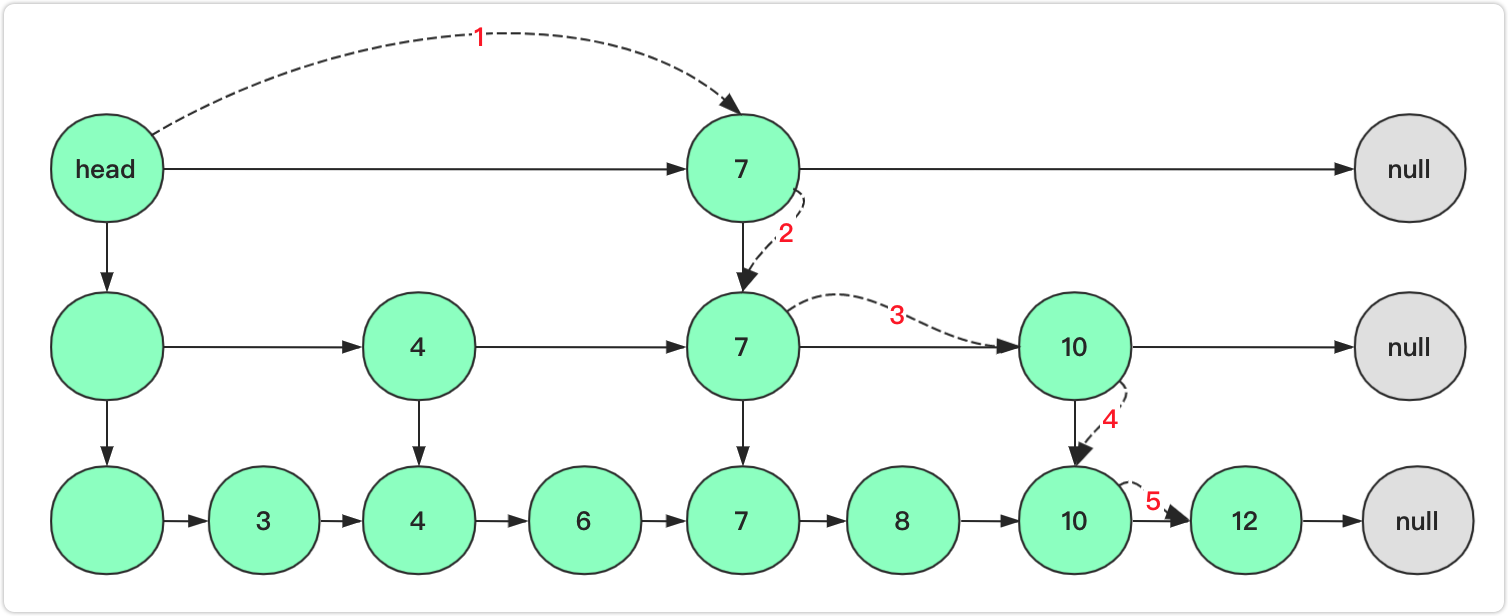
例如上图查询12节点,首先第一步从head出发发现右侧不为空,且7<12,向右;第二步右侧为null向下;第三步节点7的右侧10<12继续向右;第四步10右侧为null向下;第五步右侧12小于等于向右。第六步起始发现相等返回节点结束。
而这块的代码也非常容易:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
| public SkipNode search(int key) {
SkipNode team=headNode;
while (team!=null) {
if(team.key==key)
{
return team;
}
else if(team.right==null)
{
team=team.down;
}
else if(team.right.key>key)
{
team=team.down;
}
else
{
team=team.right;
}
}
return null;
}
|
删除操作
删除操作比起查询稍微复杂一丢丢,但是比插入简单。删除需要改变链表结构所以需要处理好节点之间的联系。对于删除操作你需要谨记以下几点:
(1)删除当前节点和这个节点的前后节点都有关系
(2)删除当前层节点之后,下一层该key的节点也要删除,一直删除到最底层
根据这两点分析一下:如果找到当前节点了,它的前面一个节点怎么查找呢?这个总不能在遍历一遍吧!有的使用四个方向的指针(上下左右)用来找到左侧节点。是可以的,但是这里可以特殊处理一下 ,不直接判断和操作节点,先找到待删除节点的左侧节点。通过这个节点即可完成删除,然后这个节点直接向下去找下一层待删除的左侧节点。设置一个临时节点team=head,当team不为null具体循环流程为:
(1)如果team右侧为null,那么team=team.down(之所以敢直接这么判断是因为左侧有头结点在左侧,不用担心特殊情况)
(2)如果team右侧不 为null,并且右侧的key等于待删除的key,那么先删除节点,再team向下team=team.down为了删除下层节点。
(3)如果team右侧不 为null,并且右侧key小于待删除的key,那么team向右team=team.right。
(4)如果team右侧不 为null,并且右侧key大于待删除的key,那么team向下team=team.down,在下层继续查找删除节点。
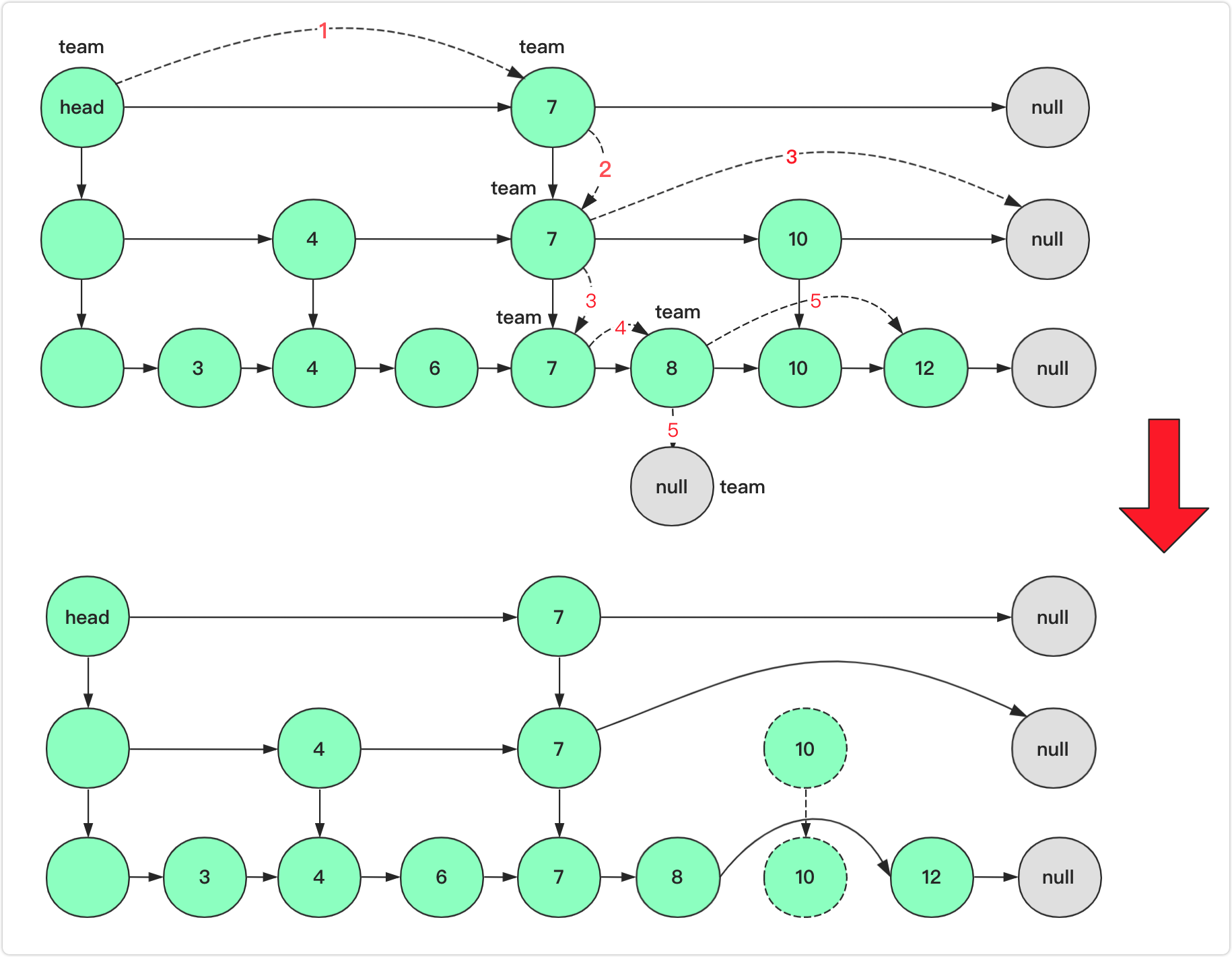
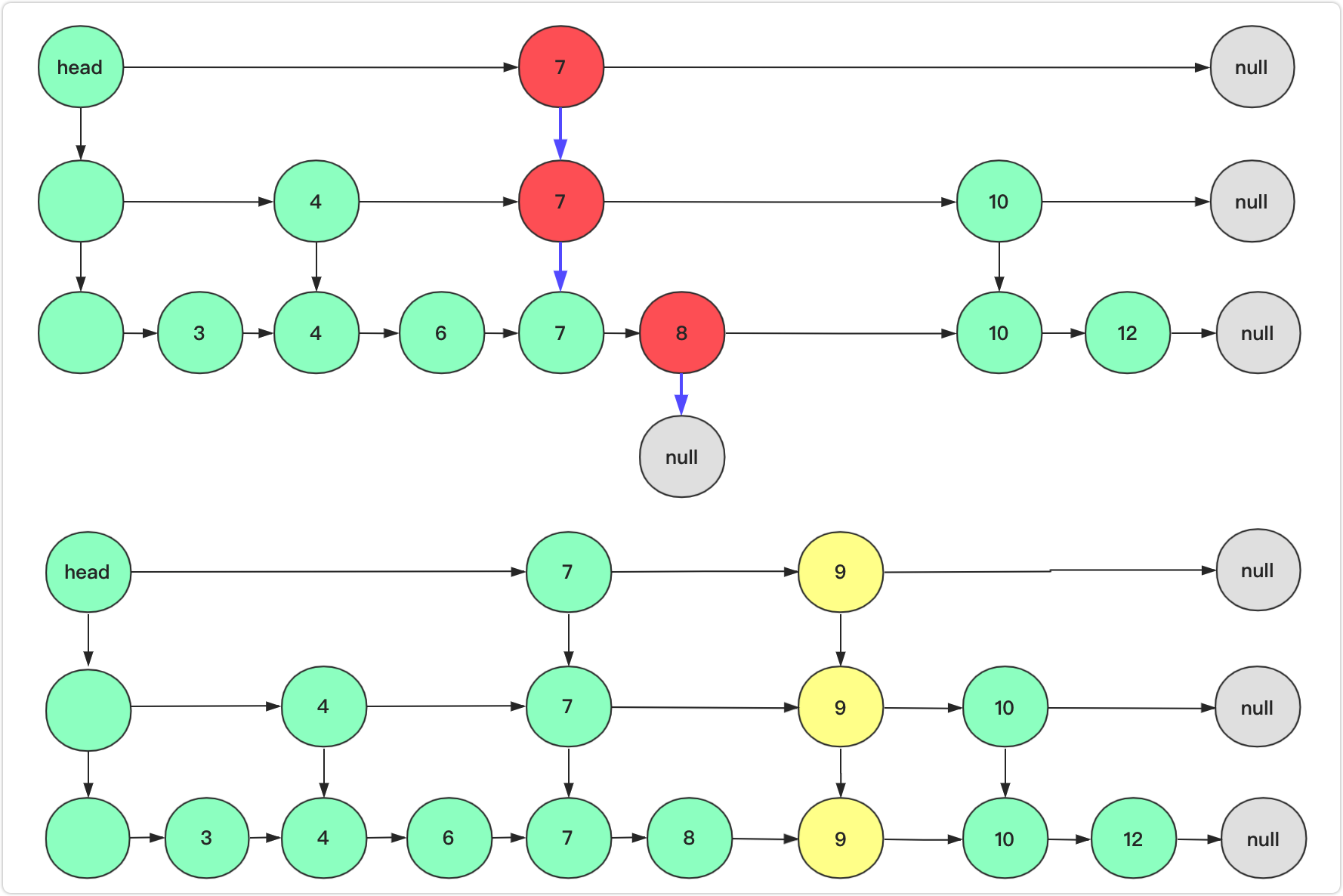
例如上图删除10节点,首先team=head从team出发,7<10向右(team=team.right后面省略);第二步右侧为null只能向下;第三部右侧为10在当前层删除10节点然后向下继续查找下一层10节点;第四步8<10向右;第五步右侧为10删除该节点并且team向下。team为null说明删除完毕退出循环。
删除操作实现的代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
| public void delete(int key)
{
SkipNode team=headNode;
while (team!=null) {
if (team.right == null) {
team=team.down;
}
else if(team.right.key==key)
{
team.right=team.right.right;
team=team.down;
}
else if(team.right.key>key)
{
team=team.down;
}
else {
team=team.right;
}
}
}
|
插入操作
插入操作在实现起来是最麻烦的,需要的考虑的东西最多。回顾查询,不需要动索引;回顾删除,每层索引如果有删除就是了。但是插入不一样了,插入需要考虑是否插入索引,插入几层等问题。由于需要插入删除所以我们肯定无法维护一个完全理想的索引结构,因为它耗费的代价太高。但我们使用随机化的方法去判断是否向上层插入索引。即产生一个[0-1]的随机数如果小于0.5就向上插入索引,插入完毕后再次使用随机数判断是否向上插入索引。运气好这个值可能是多层索引,运气不好只插入最底层(这是100%插入的)。但是索引也不能不限制高度,我们一般会设置索引最高值如果大于这个值就不往上继续添加索引了。
我们一步步剖析该怎么做,其流程为
(1)首先通过上面查找的方式,找到待插入的左节点。插入的话最底层肯定是需要插入的,所以通过链表插入节点(需要考虑是否为末尾节点)
(2)插入完这一层,需要考虑上一层是否插入,首先判断当前索引层级,如果大于最大值那么就停止(比如已经到最高索引层了)。否则设置一个随机数1/2的概率向上插入一层索引(因为理想状态下的就是每2个向上建一个索引节点)。
(3)继续(2)的操作,直到概率退出或者索引层数大于最大索引层。
在具体向上插入的时候,实质上还有非常重要的细节需要考虑。首先如何找到上层的待插入节点 ?
这个各个实现方法可能不同,如果有左、上指向的指针那么可以向左向上找到上层需要插入的节点,但是如果只有右指向和下指向的我们也可以巧妙的借助查询过程中记录下降的节点。因为曾经下降的节点倒序就是需要插入的节点,最底层也不例外(因为没有匹配值会下降为null结束循环)。在这里我使用栈这个数据结构进行存储,当然使用List也可以。下图就是给了一个插入示意图。
其次如果该层是目前的最高层索引,需要继续向上建立索引应该怎么办?
首先跳表最初肯定是没索引的,然后慢慢添加节点才有一层、二层索引,但是如果这个节点添加的索引突破当前最高层,该怎么办呢?
这时候需要注意了,跳表的head需要改变了,新建一个ListNode节点作为新的head,将它的down指向老head,将这个head节点加入栈中(也就是这个节点作为下次后面要插入的节点),就比如上面的9节点如果运气够好在往上建立一层节点,会是这样的。
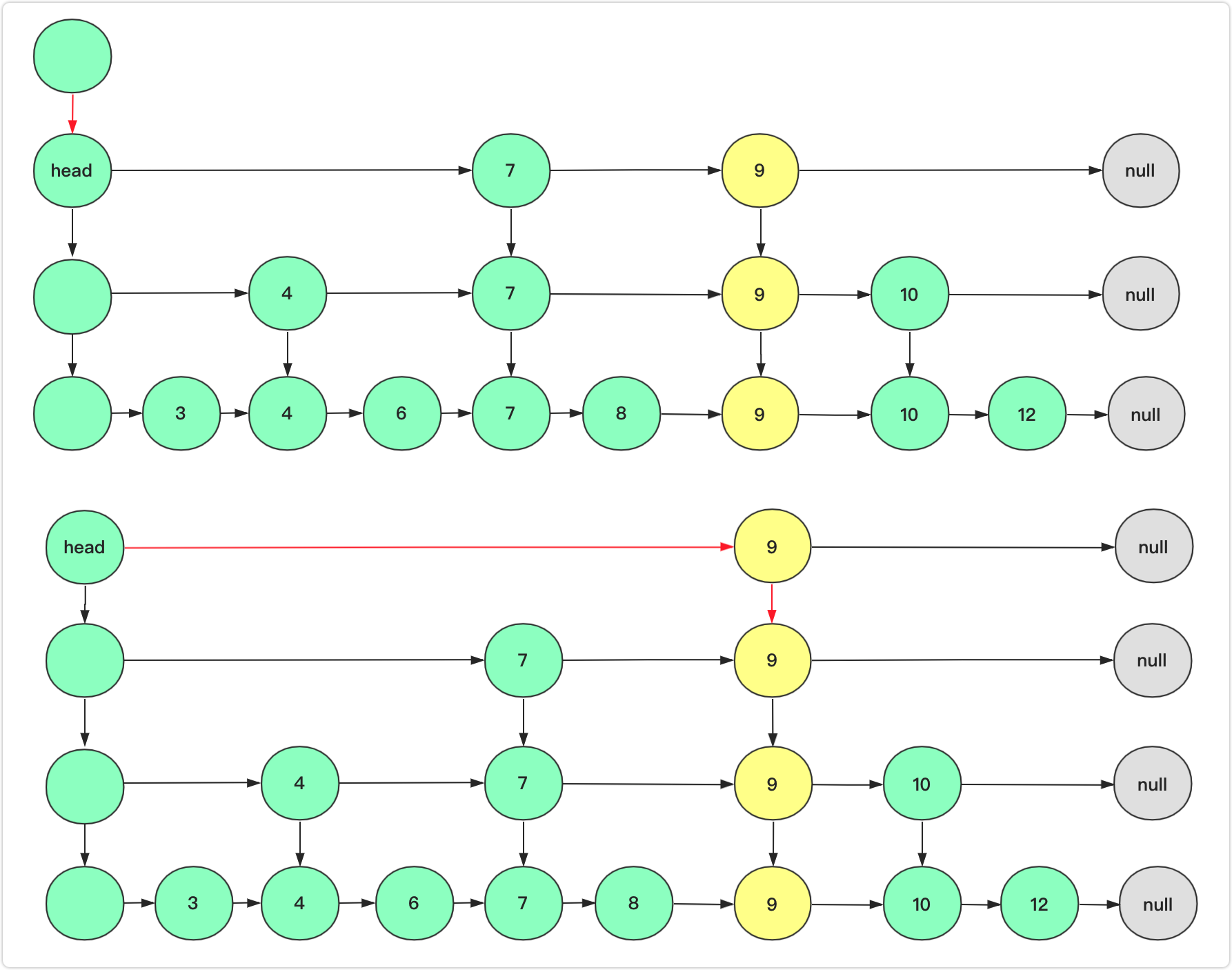
插入上层的时候注意所有节点要新建(拷贝),除了right的指向down的指向也不能忘记,down指向上一个节点可以用一个临时节点作为前驱节点。如果层数突破当前最高层,头head节点(入口)需要改变。
这部分更多的细节在代码中注释解释了,详细代码为:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
| public void add(SkipNode node)
{
int key=node.key;
SkipNode findNode=search(key);
if(findNode!=null)
{
findNode.value=node.value;
return;
}
Stack<SkipNode>stack=new Stack<SkipNode>();
SkipNode team=headNode;
while (team!=null) {
if(team.right==null)
{
stack.add(team);
team=team.down;
}
else if(team.right.key>key)
{
stack.add(team);
team=team.down;
}
else
{
team=team.right;
}
}
int level=1;
SkipNode downNode=null;
while (!stack.isEmpty()) {
team=stack.pop();
SkipNode nodeTeam=new SkipNode(node.key, node.value);
nodeTeam.down=downNode;
downNode=nodeTeam;
if(team.right==null) {
team.right=nodeTeam;
}
else {
nodeTeam.right=team.right;
team.right=nodeTeam;
}
if(level>MAX_LEVEL)
break;
double num=random.nextDouble();
if(num>0.5)
break;
level++;
if(level>highLevel)
{
highLevel=level;
SkipNode highHeadNode=new SkipNode(Integer.MIN_VALUE, null);
highHeadNode.down=headNode;
headNode=highHeadNode;
stack.add(headNode);
}
}
}
|
总结
对于上面,跳表完整分析就结束啦,当然,你可能看到不同品种跳表的实现,还有的用数组方式表示上下层的关系这样也可以,但本文只定义right和down两个方向的链表更纯正化的讲解跳表。
对于跳表以及跳表的同类竞争产品:红黑树,为啥Redis的有序集合(zset) 使用跳表呢?因为跳表除了查找插入维护和红黑树有着差不多的效率,它是个链表,能确定范围区间,而区间问题在树上可能就没那么方便查询啦。而JDK中跳跃表ConcurrentSkipListSet和ConcurrentSkipListMap。 有兴趣的也可以查阅一下源码。
完整代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
| import java.util.Random;
import java.util.Stack;
class SkipNode<T>
{
int key;
T value;
SkipNode right,down;
public SkipNode (int key,T value) {
this.key=key;
this.value=value;
}
}
public class SkipList <T> {
SkipNode headNode;
int highLevel;
Random random;
final int MAX_LEVEL = 32;
SkipList(){
random=new Random();
headNode=new SkipNode(Integer.MIN_VALUE,null);
highLevel=0;
}
public SkipNode search(int key) {
SkipNode team=headNode;
while (team!=null) {
if(team.key==key)
{
return team;
}
else if(team.right==null)
{
team=team.down;
}
else if(team.right.key>key)
{
team=team.down;
}
else
{
team=team.right;
}
}
return null;
}
public void delete(int key)
{
SkipNode team=headNode;
while (team!=null) {
if (team.right == null) {
team=team.down;
}
else if(team.right.key==key)
{
team.right=team.right.right;
team=team.down;
}
else if(team.right.key>key)
{
team=team.down;
}
else {
team=team.right;
}
}
}
public void add(SkipNode node)
{
int key=node.key;
SkipNode findNode=search(key);
if(findNode!=null)
{
findNode.value=node.value;
return;
}
Stack<SkipNode>stack=new Stack<SkipNode>();
SkipNode team=headNode;
while (team!=null) {
if(team.right==null)
{
stack.add(team);
team=team.down;
}
else if(team.right.key>key)
{
stack.add(team);
team=team.down;
}
else
{
team=team.right;
}
}
int level=1;
SkipNode downNode=null;
while (!stack.isEmpty()) {
team=stack.pop();
SkipNode nodeTeam=new SkipNode(node.key, node.value);
nodeTeam.down=downNode;
downNode=nodeTeam;
if(team.right==null) {
team.right=nodeTeam;
}
else {
nodeTeam.right=team.right;
team.right=nodeTeam;
}
if(level>MAX_LEVEL)
break;
double num=random.nextDouble();
if(num>0.5)
break;
level++;
if(level>highLevel)
{
highLevel=level;
SkipNode highHeadNode=new SkipNode(Integer.MIN_VALUE, null);
highHeadNode.down=headNode;
headNode=highHeadNode;
stack.add(headNode);
}
}
}
public void printList() {
SkipNode teamNode=headNode;
int index=1;
SkipNode last=teamNode;
while (last.down!=null){
last=last.down;
}
while (teamNode!=null) {
SkipNode enumNode=teamNode.right;
SkipNode enumLast=last.right;
System.out.printf("%-8s","head->");
while (enumLast!=null&&enumNode!=null) {
if(enumLast.key==enumNode.key)
{
System.out.printf("%-5s",enumLast.key+"->");
enumLast=enumLast.right;
enumNode=enumNode.right;
}
else{
enumLast=enumLast.right;
System.out.printf("%-5s","");
}
}
teamNode=teamNode.down;
index++;
System.out.println();
}
}
public static void main(String[] args) {
SkipList<Integer>list=new SkipList<Integer>();
for(int i=1;i<20;i++)
{
list.add(new SkipNode(i,666));
}
list.printList();
list.delete(4);
list.delete(8);
list.printList();
}
}
|