Section1 channel 使用
1.1 make channel
一种是带缓冲的channel一种是不带缓冲的channel。创建方式分别如下:
1 | // buffered |
buffered channel
如果我们创建一个带buffer的channel,底层的数据模型如下图:
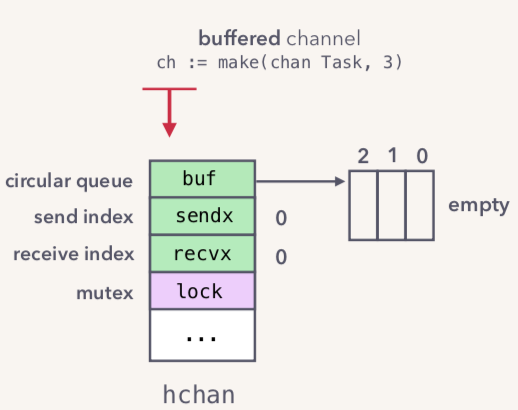
当我们向channel里面写入数据时候,会直接把数据存入circular queue(send)。当Queue存满了之后就会是如下的状态:
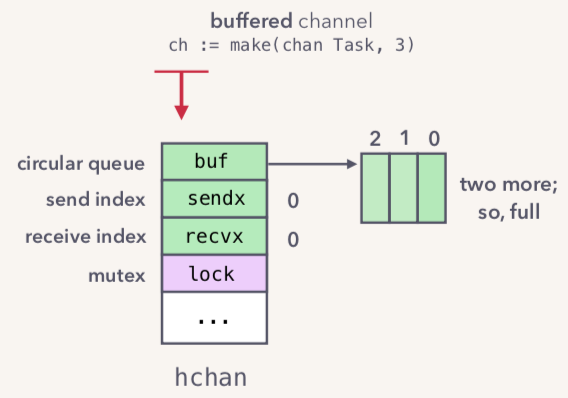
当dequeue一个元素时候,如下所示:
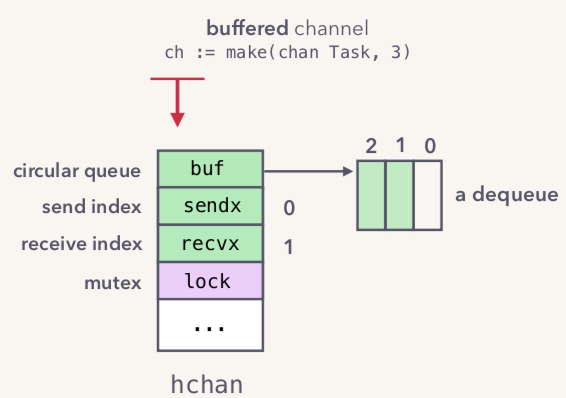
从上图可知,recvx自增加一,表示出队了一个元素,其实也就是循环数组实现FIFO语义。
那么还有一个问题,当我们新建channel的时候,底层创建的hchan数据结构是在哪里分配内存的呢?其实Section2里面源码分析时候已经做了分析,hchan是在heap里面分配的。
如下图所示:
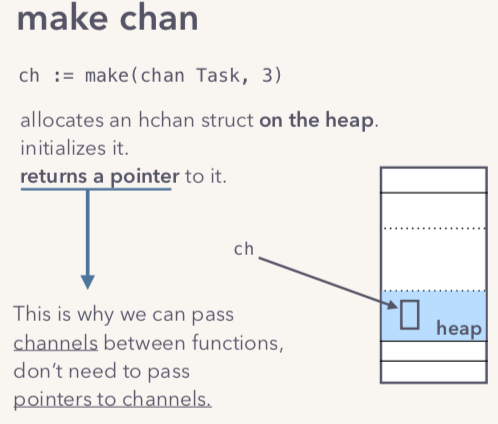
当我们使用make去创建一个channel的时候,实际上返回的是一个指向channel的pointer,所以我们能够在不同的function之间直接传递channel对象,而不用通过指向channel的指针。
1.2 sends and receives
不同goroutine在channel上面进行读写时,涉及到的过程比较复杂,比如下图:

上图中G1会往channel里面写入数据,G2会从channel里面读取数据。
G1作用于底层hchan的流程如下图:
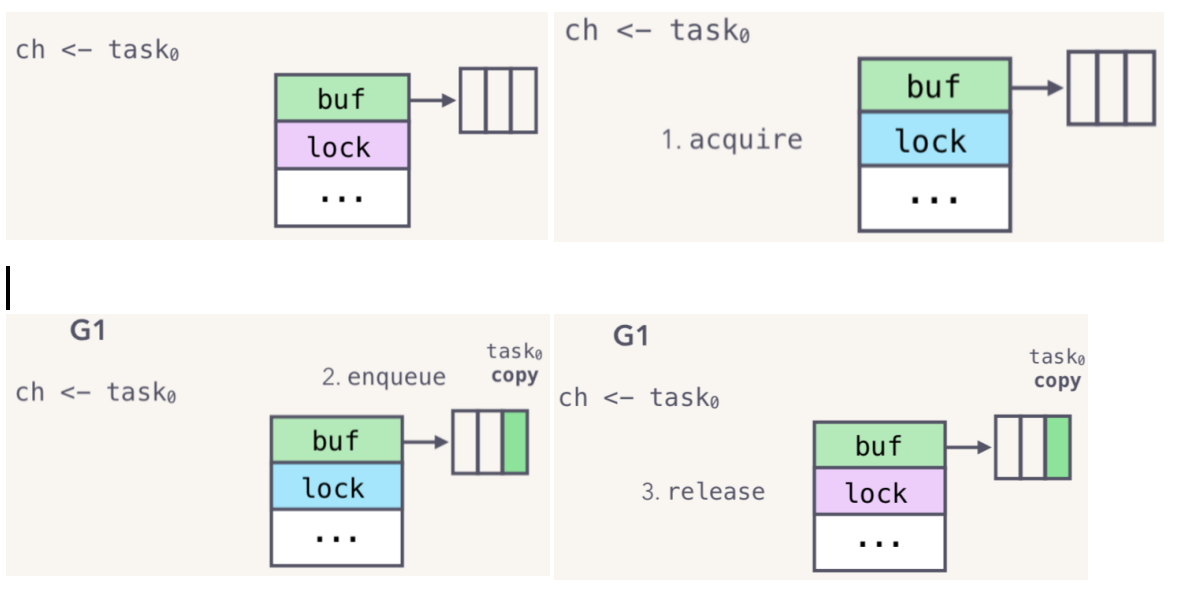
- 先获取全局锁;
- 然后enqueue元素(通过移动拷贝的方式);
- 释放锁;
G2读取时候作用于底层数据结构流程如下图所示:
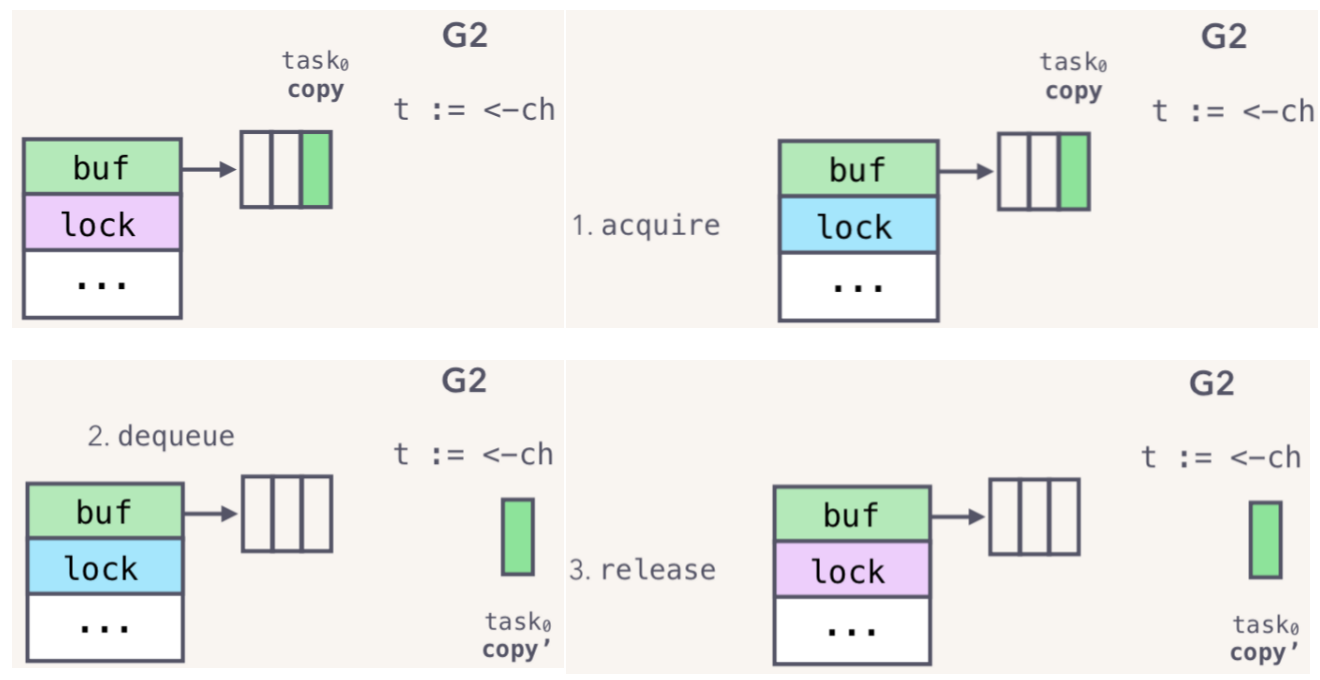
- 先获取全局锁;
- 然后dequeue元素(通过移动拷贝的方式);
- 释放锁;
上面的读写思路其实很简单,除了hchan数据结构外,不要通过共享内存去通信;而是通过通信(复制)实现共享内存。
写入满channel的场景
如下图所示:channel写入3个task之后队列已经满了,这时候G1再写入第四个task的时候会发生什么呢?

G1这时候会暂停直到出现一个receiver。
这个地方需要介绍一下Golang的scheduler的。我们知道goroutine是用户空间的线程,创建和管理协程都是通过Go的runtime,而不是通过OS的thread。
但是Go的runtime调度执行goroutine却是基于OS thread的。如下图: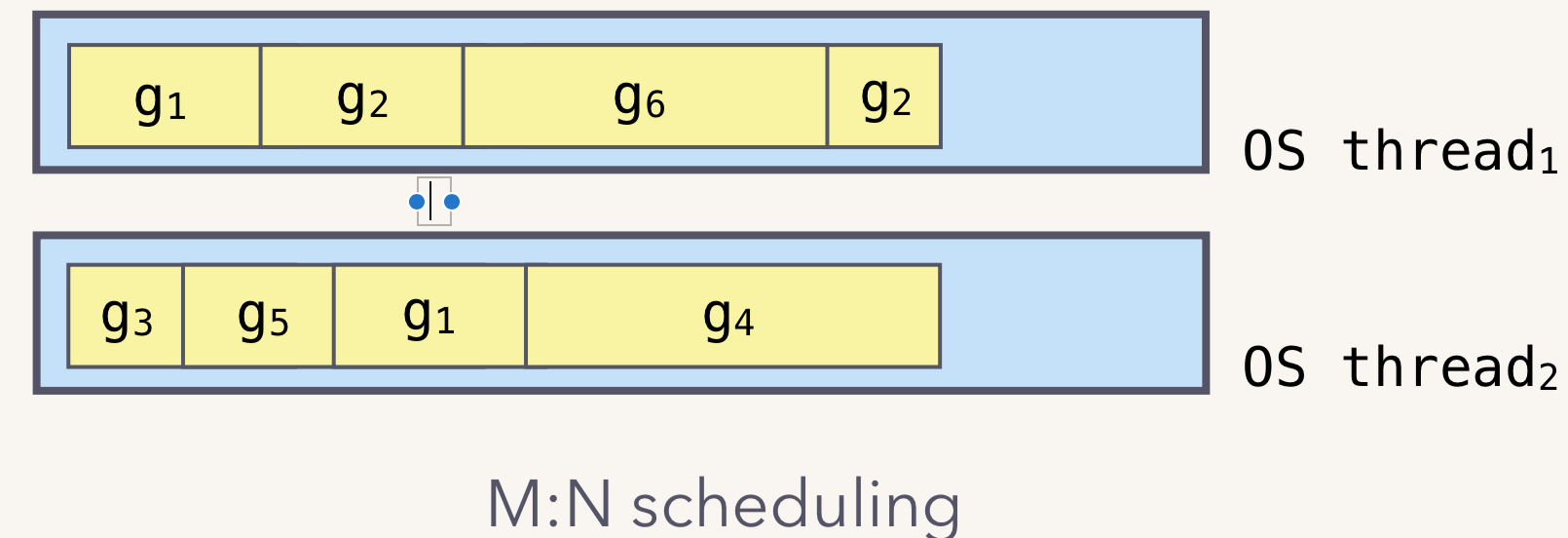
当向已经满的channel里面写入数据时候,会发生什么呢?如下图:
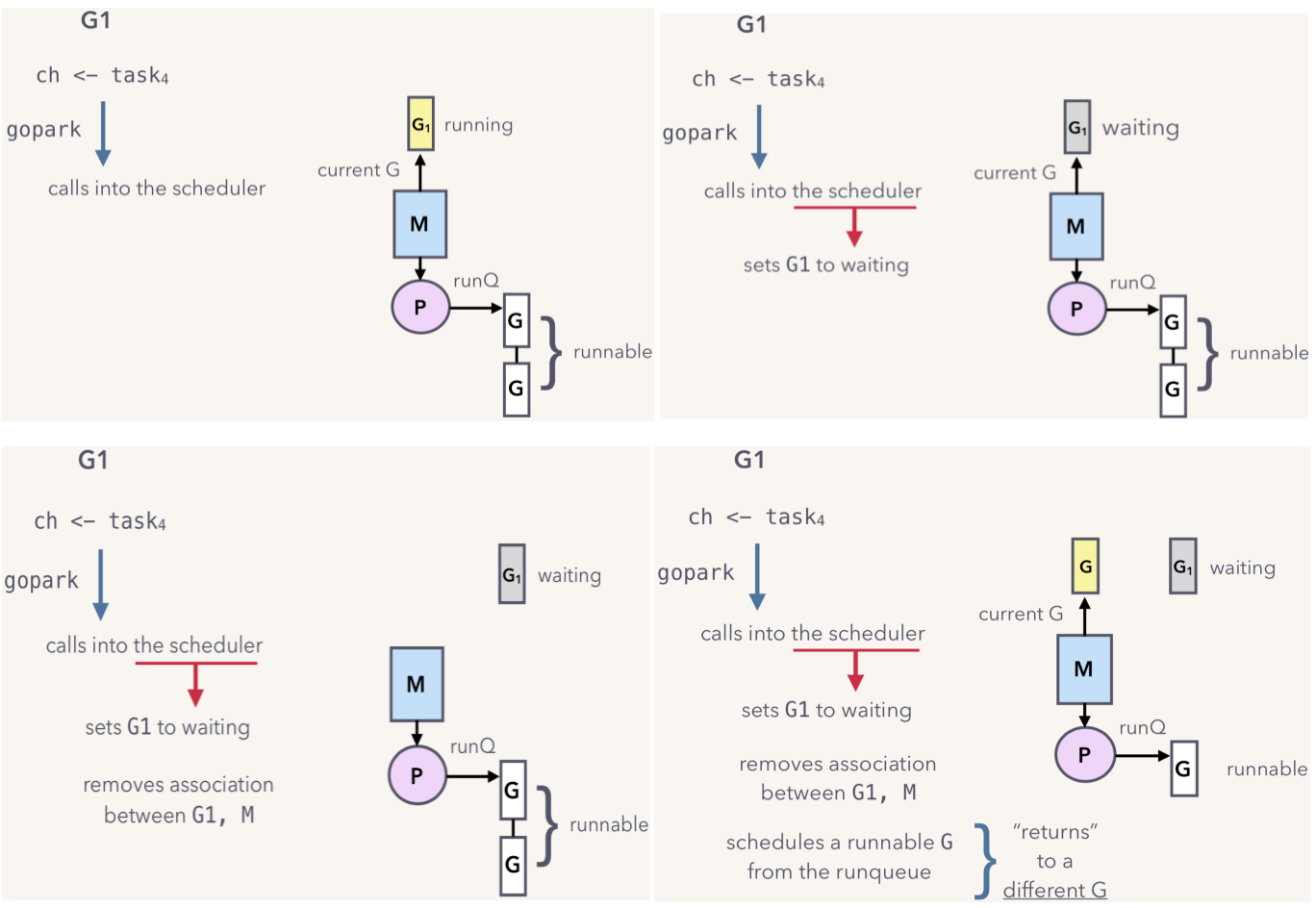
上图流程大概如下:
当前goroutine(G1)会调用gopark函数,将当前协程置为waiting状态;
将M和G1绑定关系断开;
scheduler会调度另外一个就绪态的goroutine与M建立绑定关系,然后M 会运行另外一个G。
所以整个过程中,OS thread会一直处于运行状态,不会因为协程G1的阻塞而阻塞。最后当前的G1的引用会存入channel的sender队列(队列元素是持有G1的sudog)。
那么blocked的G1怎么恢复呢?当有一个receiver接收channel数据的时候,会恢复 G1。
实际上hchan数据结构也存储了channel的sender和receiver的等待队列。数据原型如下: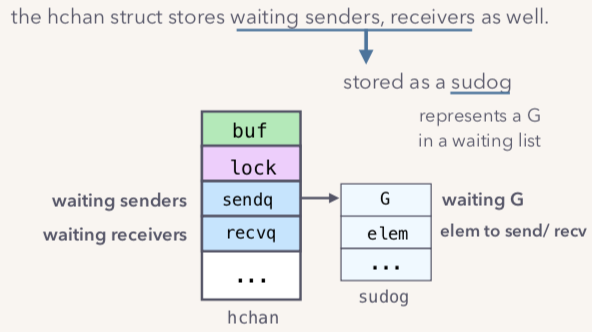
等待队列里面是sudog的单链表,sudog持有一个G代表goroutine对象引用,elem代表channel里面保存的元素。当G1执行ch<-task4的时候,G1会创建一个sudog然后保存进入sendq队列,实际上hchan结构如下图:
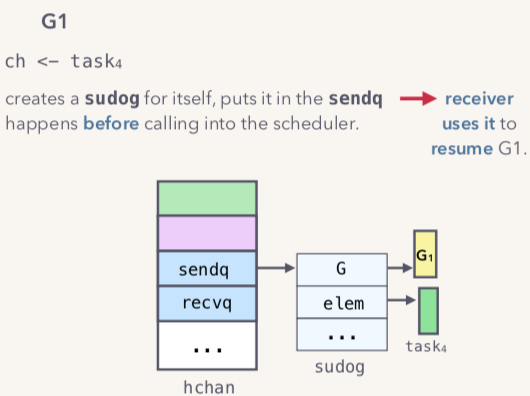
这个时候,如果G2进行一个读取channel操作,读取前和读取后的变化图如下图:
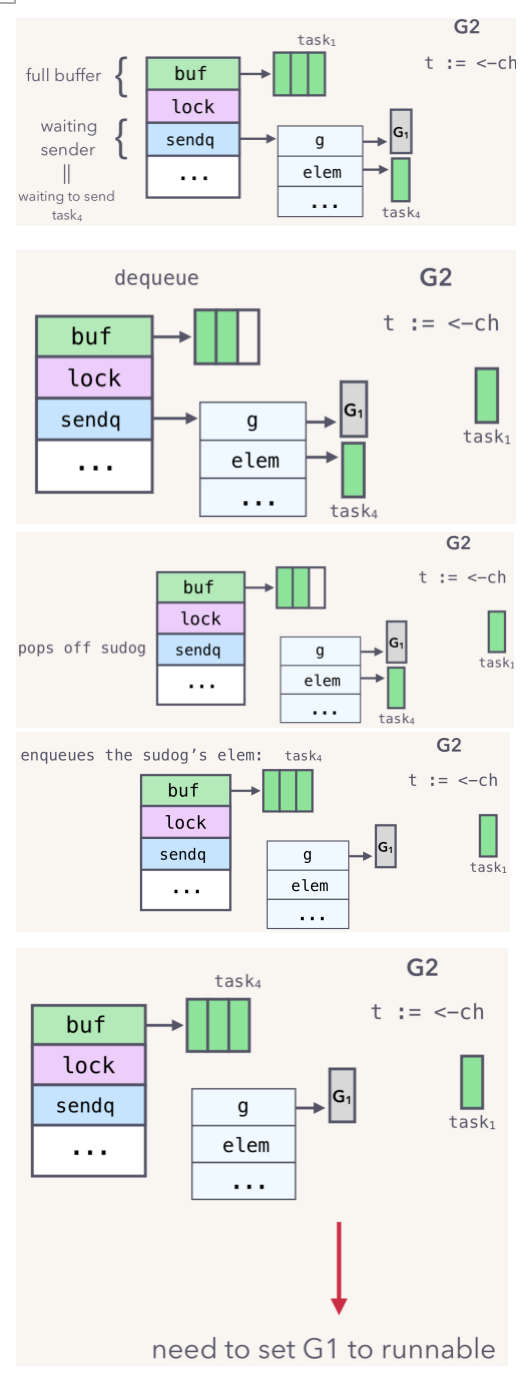
整个过程如下:
- G2调用 t:=<-ch 获取一个元素;
- 从channel的buffer里面取出一个元素task1;
- 从sender等待队列里面pop一个sudog;
- 将task4复制buffer中task1的位置,然后更新buffer的sendx和recvx索引值;
- 这时候需要将G1置为Runable状态,表示G1可以恢复运行;
这个时候将G1恢复到可运行状态需要scheduler的参与。G2会调用goready(G1)来唤醒G1。流程如下图所示:
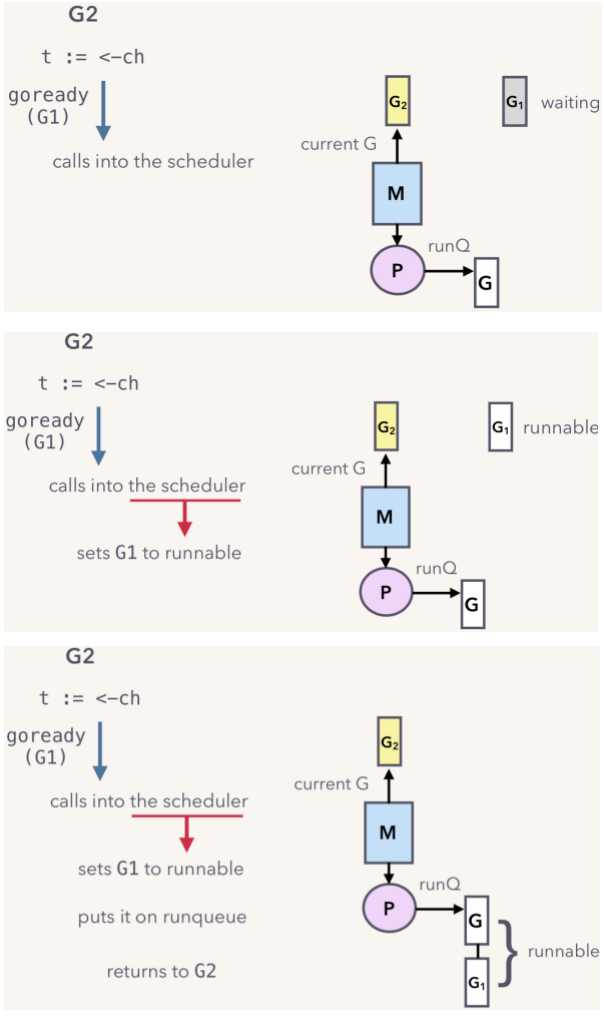
- 首先G2会调用goready(G1),唤起scheduler的调度;
- 将G1设置成Runable状态;
- G1会加入到局部调度器P的local queue队列,等待运行。
读取空channel的场景
当channel的buffer里面为空时,这时候如果G2首先发起了读取操作。如下图:
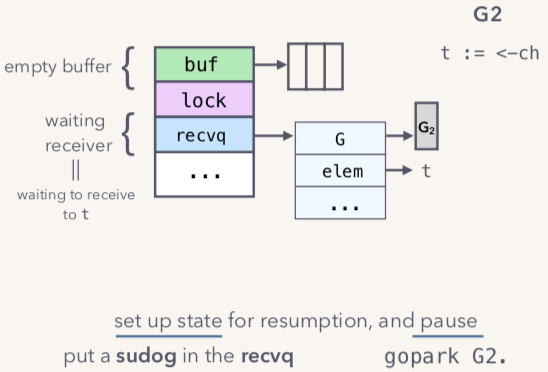
会创建一个sudog,将代表G2的sudog存入recvq等待队列。然后G2会调用gopark函数进入等待状态,让出OS thread,然后G2进入阻塞态。
这个时候,如果有一个G1执行写入操作,最直观的流程就是:
将recvq中的task存入buffer;
goready(G2) 唤醒G2;
**但是**我们有更加智能的方法:direct send; 其实也就是G1直接把数据写入到G2中的elem中,这样就不用走G2中的elem复制到buffer中,再从buffer复制给G1。如下图:
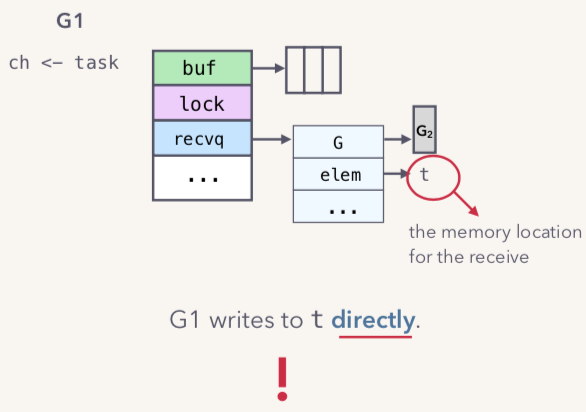
具体过程就是G1直接把数据写入到G2的栈中。这样 G2 不需要去获取channel的全局锁和操作缓冲。Section2 channel源码
2.1 channel数据存储结构
在源码runtime/chan.go 里面定义了channel的数据模型,channel可以理解成一个缓冲队列,这个缓冲队列用来存储元素,并且提供FIFO的语义。源码如下:
1 | type hchan struct { |
channel的数据结构相对比较简单,主要是两个结构:
1)一个数组实现的环形队列,数组有两个下标索引分别表示读写的索引,用于保存channel缓冲区数据。
2)channel的send和recv队列,队列里面都是持有goroutine的sudog元素,队列都是双链表实现的。
3)channel的全局锁。
2.2 环形队列
chan内部实现了一个环形队列作为其缓冲区,队列的长度是创建chan时指定的。
下图展示了一个可缓存6个元素的channel示意图:
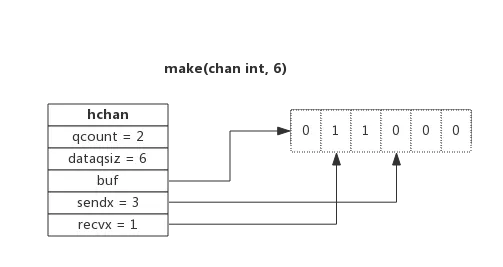
- dataqsiz指示了队列长度为6,即可缓存6个元素;
- buf指向队列的内存,队列中还剩余两个元素;
- qcount表示队列中还有两个元素;
- sendx指示后续写入的数据存储的位置,取值[0, 6);
- recvx指示从该位置读取数据, 取值[0, 6);
2.3 等待队列
从channel读数据,如果channel缓冲区为空或者没有缓冲区,当前goroutine会被阻塞。
向channel写数据,如果channel缓冲区已满或者没有缓冲区,当前goroutine会被阻塞。
被阻塞的goroutine将会挂在channel的等待队列中:
- 因读阻塞的goroutine会被向channel写入数据的goroutine唤醒;
- 因写阻塞的goroutine会被从channel读数据的goroutine唤醒;
下图展示了一个没有缓冲区的channel,有几个goroutine阻塞等待读数据:
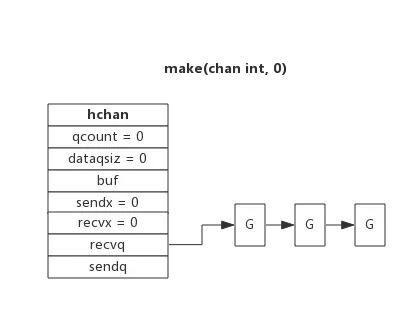
注意,一般情况下recvq和sendq至少有一个为空。只有一个例外,那就是同一个goroutine使用select语句向channel一边写数据,一边读数据。
2.4 类型信息
一个channel只能传递一种类型的值,类型信息存储在hchan数据结构中。
- elemtype代表类型,用于数据传递过程中的赋值;
- elemsize代表类型大小,用于在buf中定位元素位置。
2.5 锁
一个channel同时仅允许被一个goroutine读写,为简单起见,本章后续部分说明读写过程时不再涉及加锁和解锁。
Section3 channel读写
3.1 创建channel
我们新建一个channel的时候一般使用 make(chan, n) 语句,这个语句的执行编译器会重写然后执行 chan.go里面的 makechan函数。函数源码如下:
1 | func makechan(t *chantype, size int) *hchan { |
函数接收两个参数,一个是channel里面保存的元素的数据类型,一个是缓冲的容量(如果为0表示是非缓冲buffer),创建流程如下:
- 根据传递的缓冲大小size是否为零,分别创建不带buffer的channel或则带size大小的缓冲channel:
- 对于不带缓冲channel,申请一个hchan数据结构的内存大小;
- 对于带缓冲channel,new一个hchan对象,并初始化buffer内存
- 更新 chan中循环队列的关键属性:elemsize、elemtype、dataqsiz。
创建channel的过程实际上是初始化hchan结构。其中类型信息和缓冲区长度由make语句传入,buf的大小则与元素大小和缓冲区长度共同决定。
创建channel的伪代码如下所示:
1 | func makechan(t *chantype, size int) *hchan { |
3.2 协程向channel写入数据(goroutine sender data)
所有执行 c < ep 将ep发送到channel的代码,最后都会调用到chan.go里面的 chansend函数。
函数的定义如下:
1 | func chansend(c *hchan, ep unsafe.Pointer, block bool, callerpc uintptr) bool { |
函数有三个参数,第一个代表channel的数据结构,第二个是要指向写入的数据的指针,第三个block代表写入操作是否阻塞。

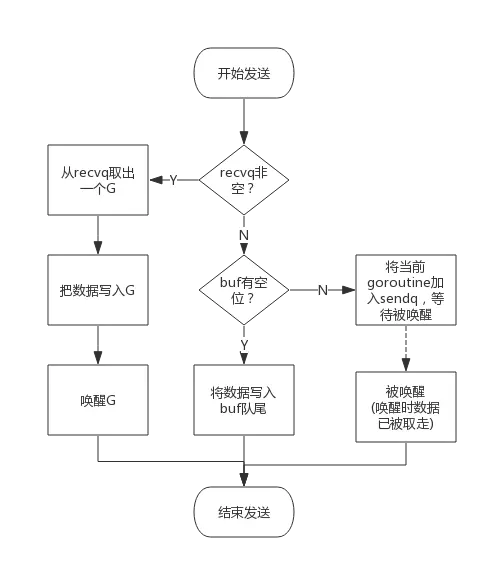
向一个channel中写数据简单过程如下:
- 如果等待接收队列recvq不为空,说明缓冲区中没有数据或者没有缓冲区,此时直接从recvq取出G,并把数据写入,最后把该G唤醒,结束发送过程;
- 如果缓冲区中有空余位置,将数据写入缓冲区,结束发送过程;
- 如果缓冲区中没有空余位置,将待发送数据写入G,将当前G加入sendq,进入睡眠,等待被读goroutine唤醒;
流程图如下:
3.3 协程从channel接收数据(goroutine receive data)
所有执行 ep < c 使用ep接收channel数据的代码,最后都会调用到chan.go里面的 chanrecv函数。
函数的定义如下:
1 | func chanrecv(c *hchan, ep unsafe.Pointer, block bool) (selected, received bool) { |
从源码注释就可以知道,该函数从channel里面接收数据,然后将接收到的数据写入到ep指针指向的对象里面。
还有一个参数block,表示当channel无法返回数据时是否阻塞等待。当block=false并且channel里面没有数据时候,函数直接返回(false,false)。
从一个channel读数据简单过程如下:
- 如果等待发送队列sendq不为空,且没有缓冲区,直接从sendq中取出G,把G中数据读出,最后把G唤醒,结束读取过程;
- 如果等待发送队列sendq不为空,此时说明缓冲区已满,从缓冲区中首部读出数据,把G中数据写入缓冲区尾部,把G唤醒,结束读取过程;
- 如果缓冲区中有数据,则从缓冲区取出数据,结束读取过程;
- 将当前goroutine加入recvq,进入睡眠,等待被写goroutine唤醒;
简单流程图如下:

3.4 关闭channel
当我们执行channel的close操作的时候会关闭channel。
关闭的主要流程如下所示:
- 获取全局锁;
- 设置channel数据结构chan的关闭标志位;
- 获取当前channel上面的读goroutine并链接成链表;
- 获取当前channel上面的写goroutine然后拼接到前面的读链表后面;
- 释放全局锁;
- 唤醒所有的读写goroutine。
关闭channel时会把recvq中的G全部唤醒,本该写入G的数据位置为nil。把sendq中的G全部唤醒,但这些G会panic。
除此之外,panic出现的常见场景还有:
- 关闭值为nil的channel
- 关闭已经被关闭的channel
- 向已经关闭的channel写数据
Section4 常见用法
4.1 单向channel
单向channel指只能用于发送或接收数据,实际上并没有单向channel。
我们知道channel可以通过参数传递,所谓单向channel只是对channel的一种使用限制,这跟C语言使用const修饰函数参数为只读是一个道理。
- func readChan(chanName <-chan int): 通过形参限定函数内部只能从channel中读取数据
- func writeChan(chanName chan<- int): 通过形参限定函数内部只能向channel中写入数据
一个简单的示例程序如下:
1 | func readChan(chanName <-chan int) { |
mychan是个正常的channel,而readChan()参数限制了传入的channel只能用来读,writeChan()参数限制了传入的channel只能用来写。
4.2 select
使用select可以监控多channel,比如监控多个channel,当其中某一个channel有数据时,就从其读出数据。
一个简单的示例程序如下:
1 | package main |
程序中创建两个channel: chan1和chan2。函数addNumberToChan()函数会向两个channel中周期性写入数据。通过select可以监控两个channel,任意一个可读时就从其中读出数据。
程序输出如下:
1 | D:\SourceCode\GoExpert\src>go run main.go |
从输出可见,从channel中读出数据的顺序是随机的,事实上select语句的多个case执行顺序是随机的,关于select的实现原理会有专门章节分析。
通过这个示例想说的是:select的case语句读channel不会阻塞,尽管channel中没有数据。这是由于case语句编译后调用读channel时会明确传入不阻塞的参数,此时读不到数据时不会将当前goroutine加入到等待队列,而是直接返回。
4.3 range
通过range可以持续从channel中读出数据,好像在遍历一个数组一样,当channel中没有数据时会阻塞当前goroutine,与读channel时阻塞处理机制一样。
1 | func chanRange(chanName chan int) { |
注意:如果向此channel写数据的goroutine退出时,系统检测到这种情况后会panic,否则range将会永久阻塞。