Lucene是apache软件基金会4 jakarta项目组的一个子项目,是一个开放源代码的全文检索引擎工具包,但它不是一个完整的全文检索引擎,而是一个全文检索引擎的架构,提供了完整的查询引擎和索引引擎,部分文本分析引擎(英文与德文两种西方语言)。Lucene的目的是为软件开发人员提供一个简单易用的工具包,以方便的在目标系统中实现全文检索的功能,或者是以此为基础建立起完整的全文检索引擎
全文检索概述
比如,我们一个文件夹中,或者一个磁盘中有很多的文件,记事本、world、Excel、pdf,我们想根据其中的关键词搜索包含的文件。例如,我们输入Lucene,所有内容含有Lucene的文件就会被检查出来。这就是所谓的全文检索。
因此,很容易的我们想到,应该建立一个关键字与文件的相关映射,盗用ppt中的一张图,很明白的解释了这种映射如何实现。
倒排索引
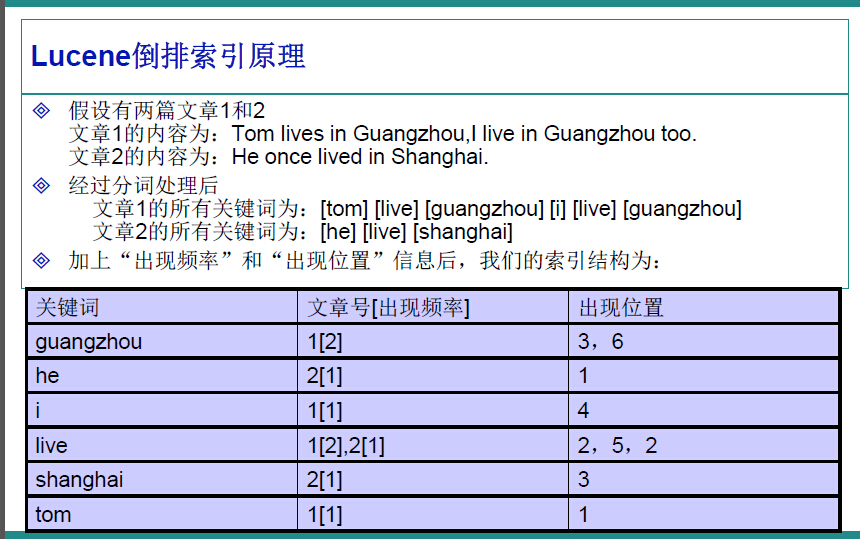
有了这种映射关系,我们就来看看Lucene的架构设计。 下面是Lucene的资料必出现的一张图,但也是其精髓的概括。
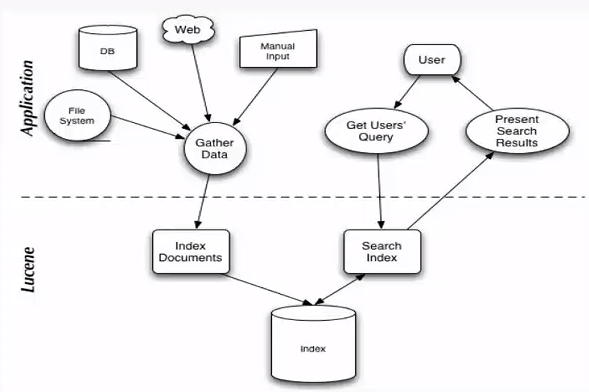
可以看到,Lucene的使用主要体现在两个步骤:
1 创建索引,通过IndexWriter对不同的文件进行索引的创建,并将其保存在索引相关文件存储的位置中。
2 通过索引查寻关键字相关文档。
在Lucene中,就是使用这种“倒排索引”的技术,来实现相关映射。
Lucene数学模型
文档、域、词元
文档是Lucene搜索和索引的原子单位,文档为包含一个或者多个域的容器,而域则是依次包含“真正的”被搜索的内容,域值通过分词技术处理,得到多个词元。
For Example,一篇小说(斗破苍穹)信息可以称为一个文档,小说信息又包含多个域,例如:标题(斗破苍穹)、作者、简介、最后更新时间等等,对标题这个域采用分词技术又可以得到一个或者多个词元(斗、破、苍、穹)。
Lucene文件结构
层次结构
index 一个索引存放在一个目录中
segment 一个索引中可以有多个段,段与段之间是独立的,添加新的文档可能产生新段,不同的段可以合并成一个新段
document 文档是创建索引的基本单位,不同的文档保存在不同的段中,一个段可以包含多个文档
field 域,一个文档包含不同类型的信息,可以拆分开索引
term 词,索引的最小单位,是经过词法分析和语言处理后的数据。
正向信息
按照层次依次保存了从索引到词的包含关系:index–>segment–>document–>field–>term。
反向信息
反向信息保存了词典的倒排表映射:term–>document
IndexWriter lucene中最重要的的类之一,它主要是用来将文档加入索引,同时控制索引过程中的一些参数使用。
Analyzer 分析器,主要用于分析搜索引擎遇到的各种文本。常用的有StandardAnalyzer分析器,StopAnalyzer分析器,WhitespaceAnalyzer分析器等。
Directory 索引存放的位置;lucene提供了两种索引存放的位置,一种是磁盘,一种是内存。一般情况将索引放在磁盘上;相应地lucene提供了FSDirectory和RAMDirectory两个类。
Document 文档;Document相当于一个要进行索引的单元,任何可以想要被索引的文件都必须转化为Document对象才能进行索引。
Field 字段。
IndexSearcher 是lucene中最基本的检索工具,所有的检索都会用到IndexSearcher工具;
Query 查询,lucene中支持模糊查询,语义查询,短语查询,组合查询等等,如有TermQuery,BooleanQuery,RangeQuery,WildcardQuery等一些类。
QueryParser 是一个解析用户输入的工具,可以通过扫描用户输入的字符串,生成Query对象。
Hits 在搜索完成之后,需要把搜索结果返回并显示给用户,只有这样才算是完成搜索的目的。在lucene中,搜索的结果的集合是用Hits类的实例来表示的。